
select * from cloud;
Use SQL to query AWS, Azure, GCP, etc. with Steampipe, a new open source project from Turbot.

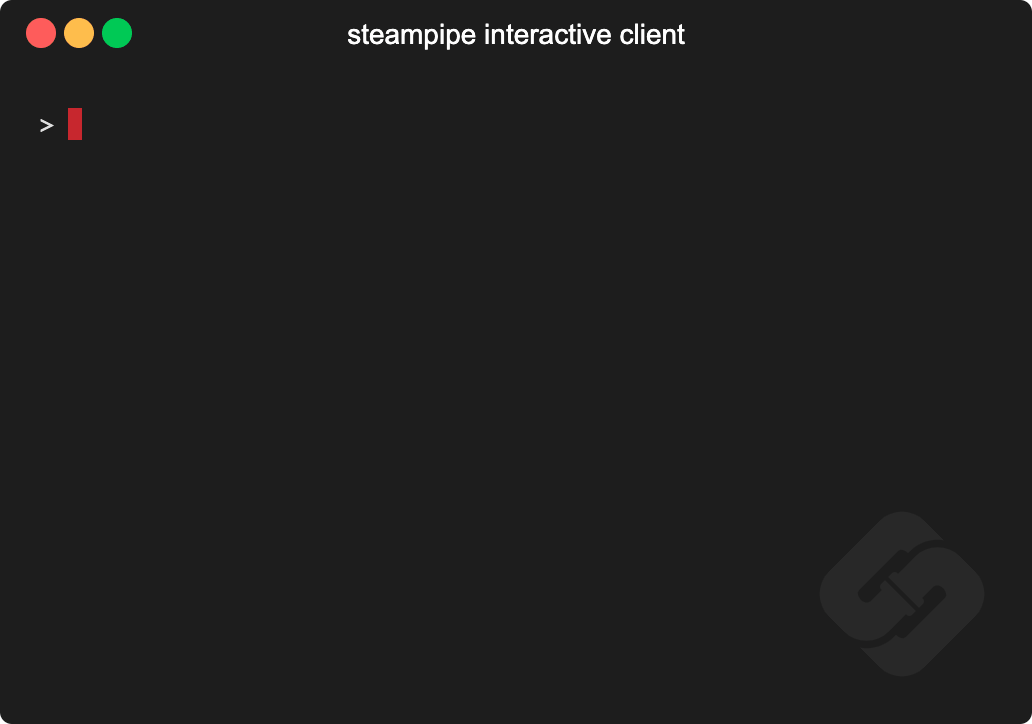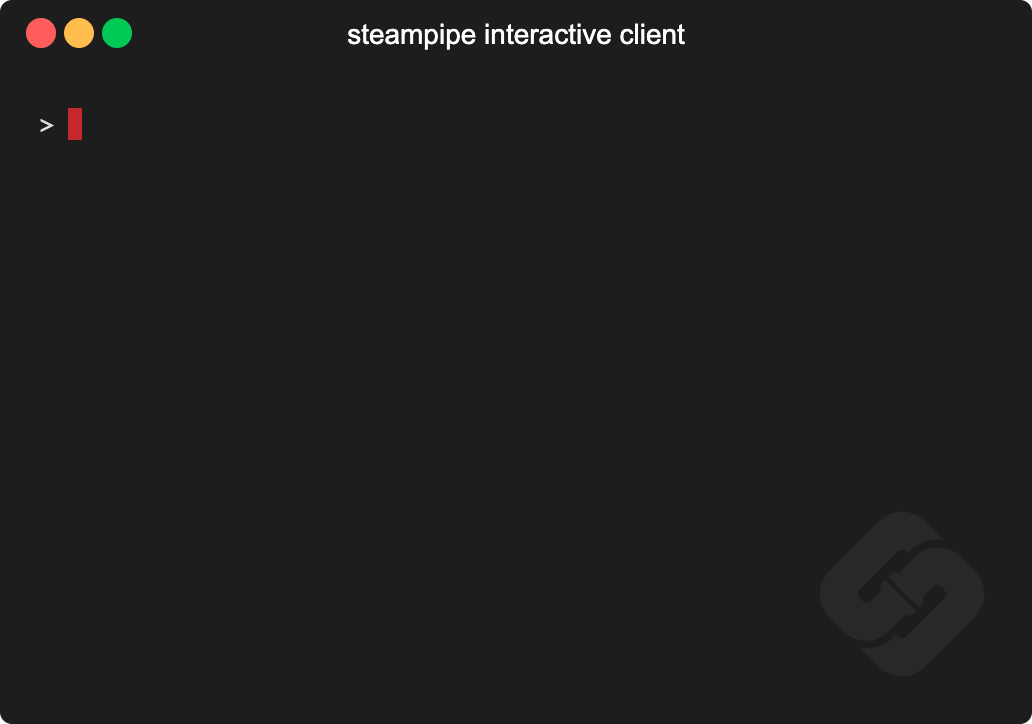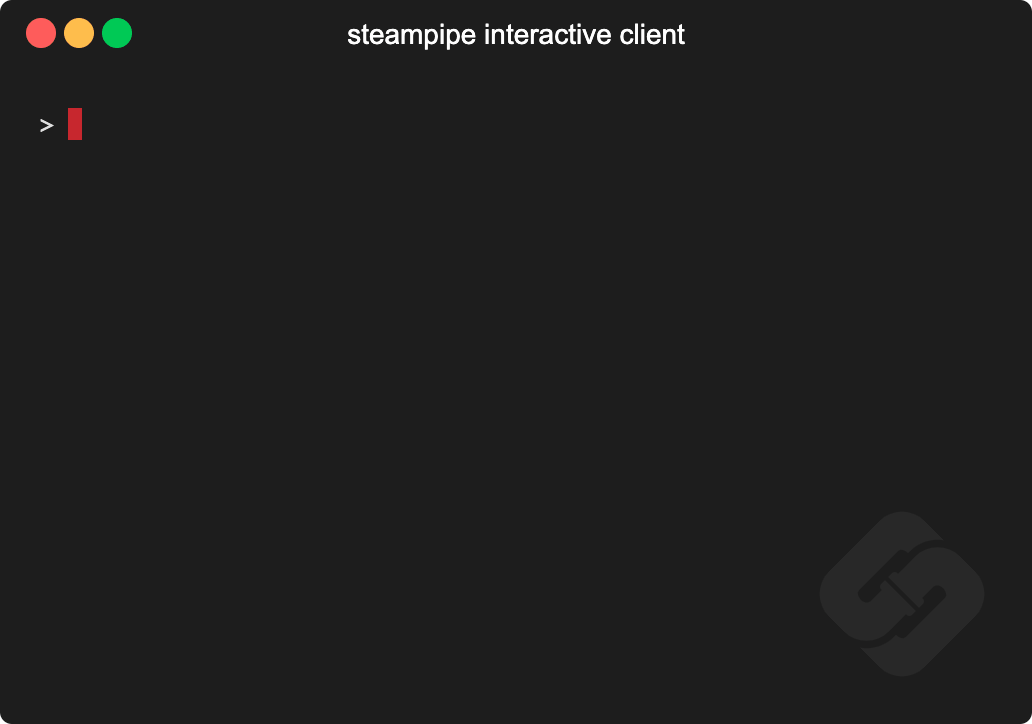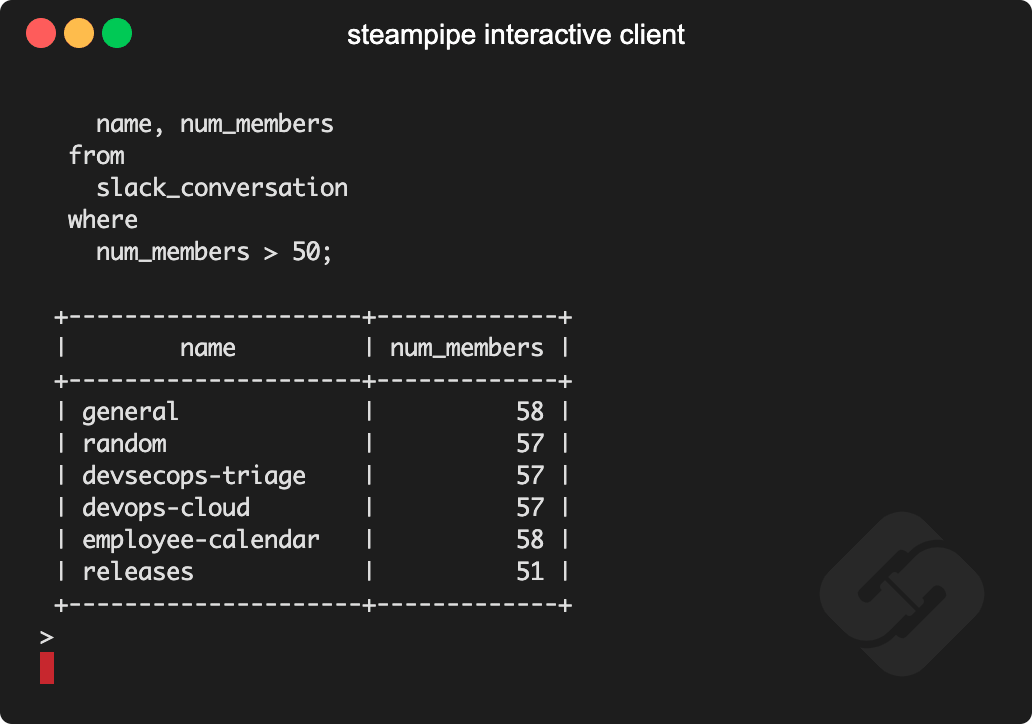
Steampipe, a new open-source tool from Turbot allows you to ask interesting questions of your cloud, one query at time.
Which users have MFA enabled right now?
select
user_id,
name,
mfa_enabled
from
github_repo_user;
What security groups are open to the world?
select
group_name,
group_id
from
aws_vpc_security_group_rule
where
type = 'ingress'
and cidr_ip = '0.0.0.0/0';
Which resources aren't tagged correctly?
select
id,
name
from
azure_compute_image
where
tags -> 'owner' is null or
tags -> 'app_id' is null;
What storage volumes are not in use?
select
volume_id,
volume_type
from
aws_ebs_volume
where
attachments is null;
What IAM Users have inline policies attached?
select
user_id,
name
from
aws_iam_user
where
inline_policies is not null;
Built for Cloud Professionals
At Turbot many of our day-to-day tasks require us to work with cloud resource metadata, sometimes as a basis for a search or filter, but also to combine with or enrich other data sources.
The existing tools we used to answer these questions were a hodgepodge of web-based consoles, CLIs, APIs, and SDKs, cobbled together with custom python or bash scripts. None of which has any level of consistency across clouds or even in a single cloud.
We needed better tooling to get our own cloud work done, so we built something to scratch that itch… and from the very first query it blew our minds. There is something very satisfying about seeing your cloud resources act like the database we always knew they were; it feels like a magic trick. Once we had it in our hands we were sure that we wanted to share it with the world, and the Steampipe open source project was born.
How does it work?
One of the goals of Steampipe was to make the first experience with it as simple as possible; we wanted zero barriers for people to download and run their first query. A lot of engineering went into how to elegantly install the dependencies and provide a first class interface to current and future plugins.
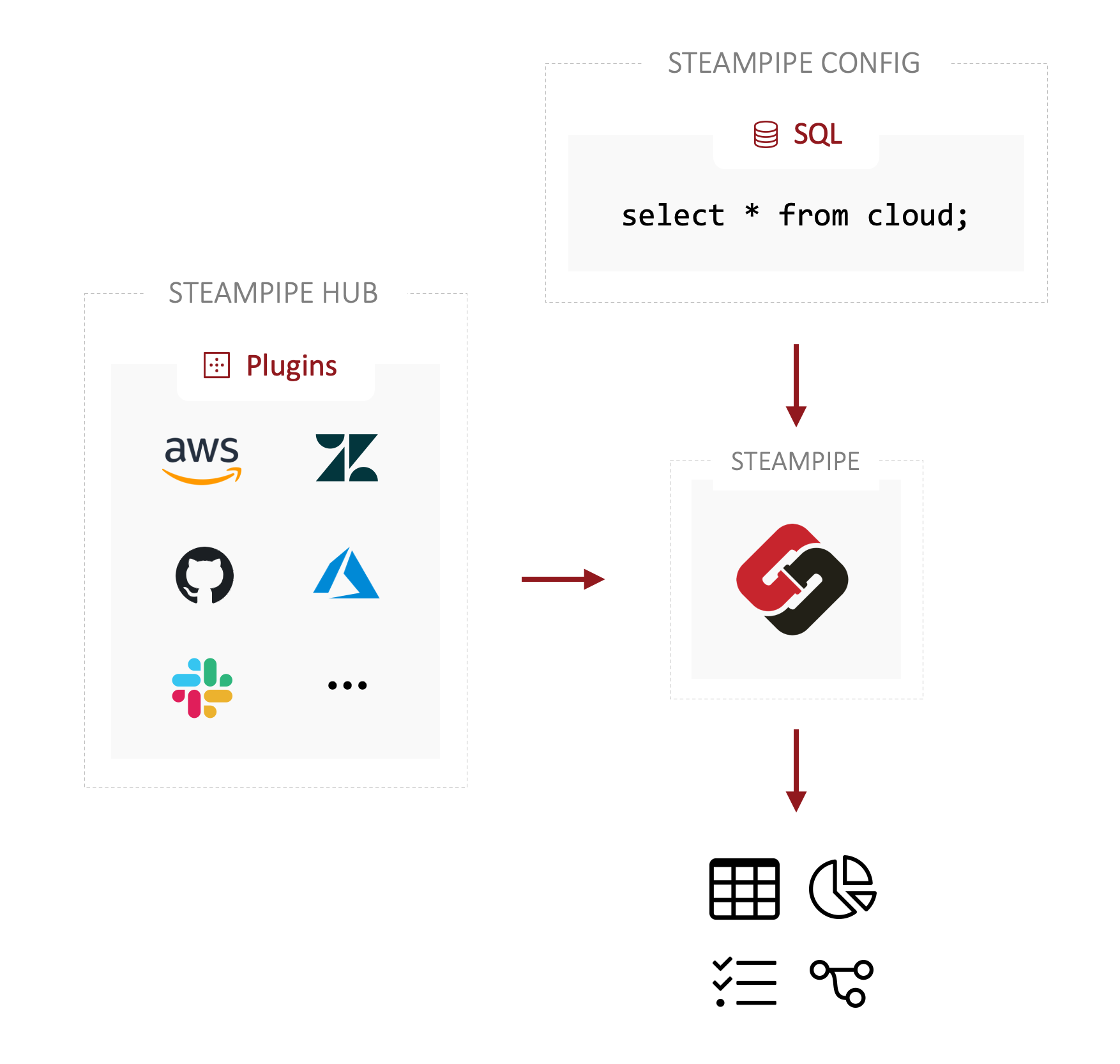
The simplicity of the user experience masks the complexity and depth of the architecture. Underlying Steampipe are three distinct software components: a CLI executable, plugin modules and a lightweight PostgreSQL background service. Data is not persisted in Postgres, instead Steampipe uses the PostgreSQL Foreign Data Wrapper to present external data as database tables. The foreign data wrapper does not directly interface with external systems, but instead relies on plugins to return data in a standard format. This approach simplifies the work needed to extend Steampipe, because PostgreSQL specific logic is encapsulated in the foreign data wrapper, while API and service-specific code resides only in the plugin.
Where do we go from here?
One of the fun things that happens when you use Steampipe every day, is that you start to wish that everything was SQL enabled.
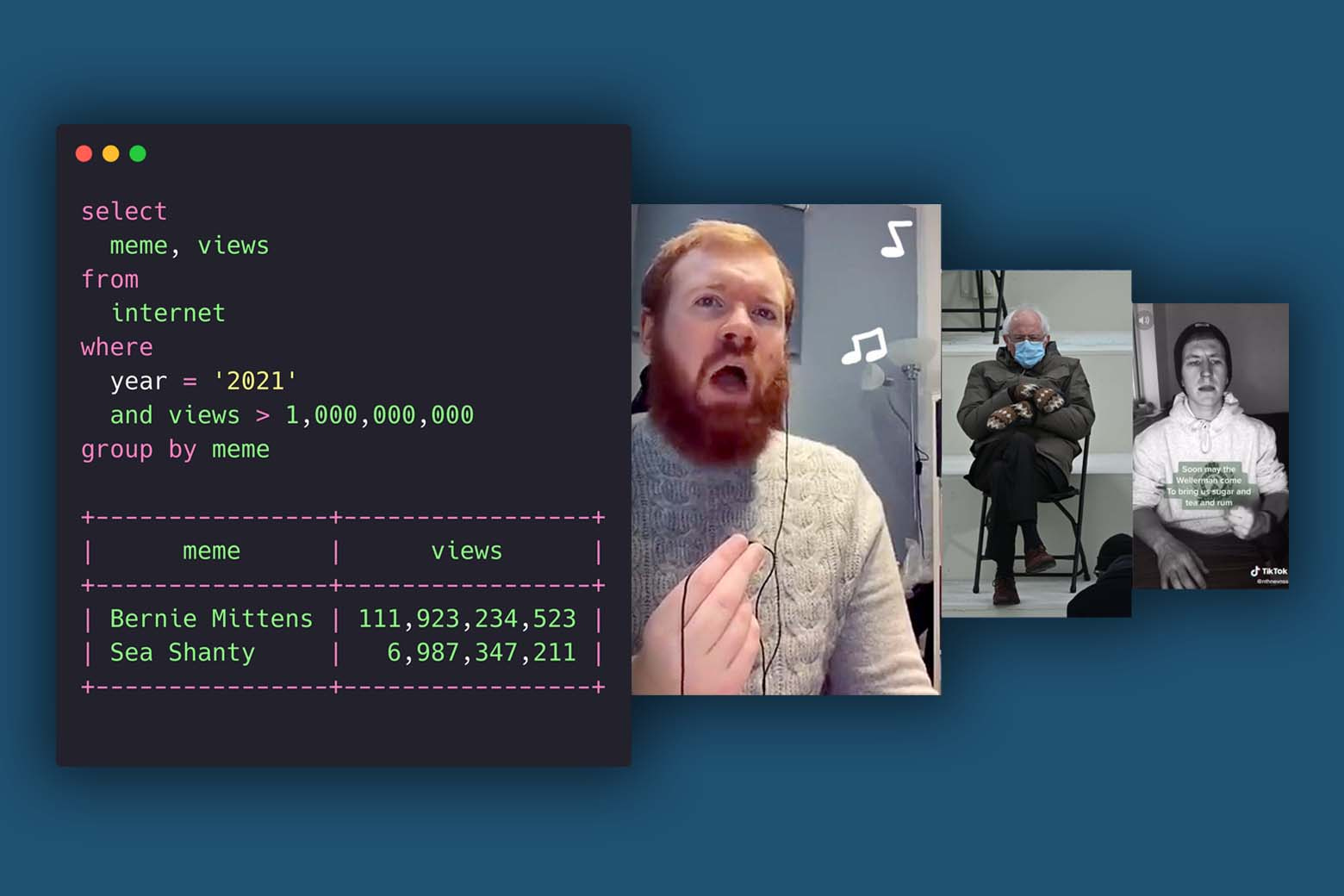
Memes aside, we are finding that we do love using Steampipe to answer real world questions outside of the public cloud space, and those ideas are making their way into the product too. For example, our customer success group was struggling to produce simple aging reports from our Zendesk platform using the built-in reporting tools.
Today, we have an automated job that runs a query against Zendesk using Steampipe and posts it to Slack every morning; It sets the focus for the day for the entire team.
select
date_part('day', now() - t.created_at) as age,
t.id,
t.status,
u.name as agent,
o.name as organization,
from
zendesk_ticket as t,
zendesk_user as u,
zendesk_organization as o
where
t.assignee_id = u.id
and
t.organization_id = o.id
and
t.status in ('open', 'pending', 'hold');
+-----+-----+---------+----------+------------------+
| AGE | ID | STATUS | AGENT | ORGANIZATION |
+-----+-----+---------+----------+------------------+
| 43 | 373 | hold | KKapoor | Haymont Tires |
| 41 | 374 | hold | JHalpert | Tract Industries |
| 40 | 375 | hold | KKapoor | Dunmore HS |
| 22 | 376 | hold | KKapoor | East PA Seminary |
| 14 | 418 | pending | JHalpert | Capital One |
| 5 | 435 | pending | DSchrute | Mr. Rammel |
| 2 | 437 | pending | JHalpert | Steamtown Mall |
| 0 | 439 | open | SHudson | Stone & Son Suit |
| 0 | 440 | hold | JHalpert | Larry Meyers |
| 0 | 441 | pending | Sudson | Blue Cross |
+-----+-----+---------+----------+------------------+
As I write this, only 2 weeks after launch, there are 11 plugins with ~200 tables published to the Steampipe Hub: https://hub.steampipe.io, including AWS, Azure, GCP, Slack, Zendesk, Github and most recently Digital Ocean. We fully intend to keep expanding the coverage, scratching any itches we find, but we are even more excited to see where the open source community takes the project and what APIs they connect Steampipe to.
Bonus: Get started today and get some free swag!
That’s right, take 2 minutes out of your day to install Steampipe and when you run your first query let us know about it! Tweet your first query to @turbothq, or head over to the Steampipe message boards, and post some feedback there on your “First Query” (Can you tell we are excited about this?) So excited in fact, that we will handsomely reward everyone that posts #firstquery in February with Turbot and Steampipe laptop sticker swag!
Getting Started Resources
Steampipe Homepage: https://steampipe.io
Download/Install Guide: https://steampipe.io/downloads
Documentation: https://steampipe.io/docs
Open Source Repo: https://github.com/turbot/steampipe
Discussion Board: https://github.com/turbot/steampipe/discussions
Plugin Registry: https://hub.steampipe.io